12
12Artificial Intelligence is no longer confined to IT companies or limited to writing code for software development. Its applications now impact how we shop, travel, move, or consume content, with examples such as automated customer support, recommendation engines, and virtual shopping assistants.
Major cloud providers have also begun offering AI workload services, including platforms such as AWS SageMaker, AWS Bedrock, and AWS Rekognition.
However, AI computing resources are notoriously expensive. With the growing demand for innovation, organizations are facing runaway cloud spend, a challenge that already existed and is now intensified by AI workloads. Thus, cost optimization in AI in the cloud is becoming increasingly important.
In this blog, we’ll discuss top AI cost optimization strategies while ensuring it doesn’t impact innovation.
Why Is Running AI Workloads So Costly?
According to a recent report from Cushman & Wakefield, the average cost of setting up a data center in the United States can reach up to $11.6 million per megawatt of IT load. The OPEX for a 10 MW data center (a standard facility) can cost between $7 and $12 million.
And since it is a fact that AI workloads are more resource-intensive, the costs increase for platform providers and, as a result, are passed down to customers, making AI cost optimization a necessity.
Here’s a detailed breakdown of the top factors responsible for the high-cost nature of AI workloads:
Specialized Hardware Requirements
Most of the production-scale AI models require GPUs as the hardware to run. This is because GPUs are designed specifically for massive parallel processing, which is ideal for heavy matrix and tensor computations — the two things AI models primarily perform.
Simple CPUs, to compensate for a GPU-based instance, require a huge amount of RAM to offset the lack of parallelism.
To put things into perspective, while an AWS Graviton4 c8g.16xlarge instance (with 256 GB RAM) can run Llama 3 8B, a much smaller GPU-powered instance like g5.xlarge (16 GB RAM / 24 GB VRAM) can run it more efficiently.However, GPUs are expensive. A single NVIDIA H100 GPU costs around USD 40,000, and a full H100 server can reach USD 400,000. The cost is eventually passed on to the end consumer.
For example, an AWS p5.48xlarge instance costs $ 98.32 (on-demand) in US East and US West regions and costs between $24 per hour as a spot instance.
Data Gathering and Preprocessing
For training a custom model for a custom use case, a large volume of data is required. And for specific requirements and use cases, this data needs to be annotated and labeled accordingly.
The costs associated with this include storing massive datasets, often in terabytes, as well as the manual or semi-automated labeling and annotation, all of which are significant cost drivers.
There are custom providers of labeled datasets who charge a substantial amount for classifying data, which eventually serves as the foundation for training the model. AI cost optimization also extends to optimization in data gathering.
High Utilization of Computing Resources
Unlike traditional cloud resources, where there are usage spikes and lean periods, allowing for optimizations, AI workloads (such as training custom LLMs) require sustained, long-duration compute resources, leaving little room for AI cost optimization. The problem is compounded by cloud teams overprovisioning resources to be “on the safer side”.
High Data Center ExpensesData centers were already an expensive affair, and with AI workloads, the associated costs have skyrocketed. On top of the high acquisition costs of computing resources (GPUs, TPUs, etc.), power densities are significantly higher. High CPU-intensive racks can consume up to 100 kW per rack, whereas traditional EC2 racks typically use only 2–4 kW per rack.
Additionally, cooling systems also require upgrading, with advanced methods like liquid or immersion cooling, further compounding the infrastructure costs and further highlighting the importance of cost optimization in AI.
Massive Data Storage Spend
Even basic AI/ML workloads, like chatbots or OCR systems, require several terabytes of data storage. Beyond compute, storage costs should also be taken into consideration when implementing AI cost optimization plans, for services like Amazon S3, EBS, and data lakes add significantly to overall cloud spend.
Example: AI data is typically stored on Amazon S3 or EBS. While instances like m6i.large handle light compute, data-heavy tasks may use i3en.large or d3en.xlarge. Even storage alone can cost hundreds of thousands of dollars per month, depending on usage.
Achieving Cost Optimization in AI for Cloud-Based Workloads
From recommendation engines for e-commerce websites to interactive chatbots for customer support, AI has found its way into almost every industry and business utilizing a digital platform. Therefore, it is all the more important to implement AI cost optimization strategies.
Since the majority of AI/ML tools and workloads run on the cloud, here are some top tips and tricks to help you carry out cost optimization in AI:
Cut Costs with Open-Source AI Tools
For almost all AI tasks across the lifecycle, from datasets to complete models, there are free alternatives available, such as LLaMA from Meta and Mistral 7B for ML models, and datasets from platforms like Kaggle and OpenML. Leveraging these can save thousands of dollars in licensing fees and, as a result, drive AI cost optimization.
However, you’ll still need to host the model yourself, which will typically incur some costs.
For example, the Mistral 7B Multi-Model LLM bundle is available at $0.104 per hour across various instance types such as g5g.4xlarge, g5g.16xlarge, and others.
Additionally, if your dataset needs to be annotated or tailored to specific requirements, that too will require spending.
Explore GPU Options other than NVIDIA Hardware
While NVIDIA GPUs have been the go-to for AI workloads for organizations, they are considered to be steeply priced. For instance, NVIDIA’s H100 (considered to be the base model GPU for AI workloads) costs $30k.
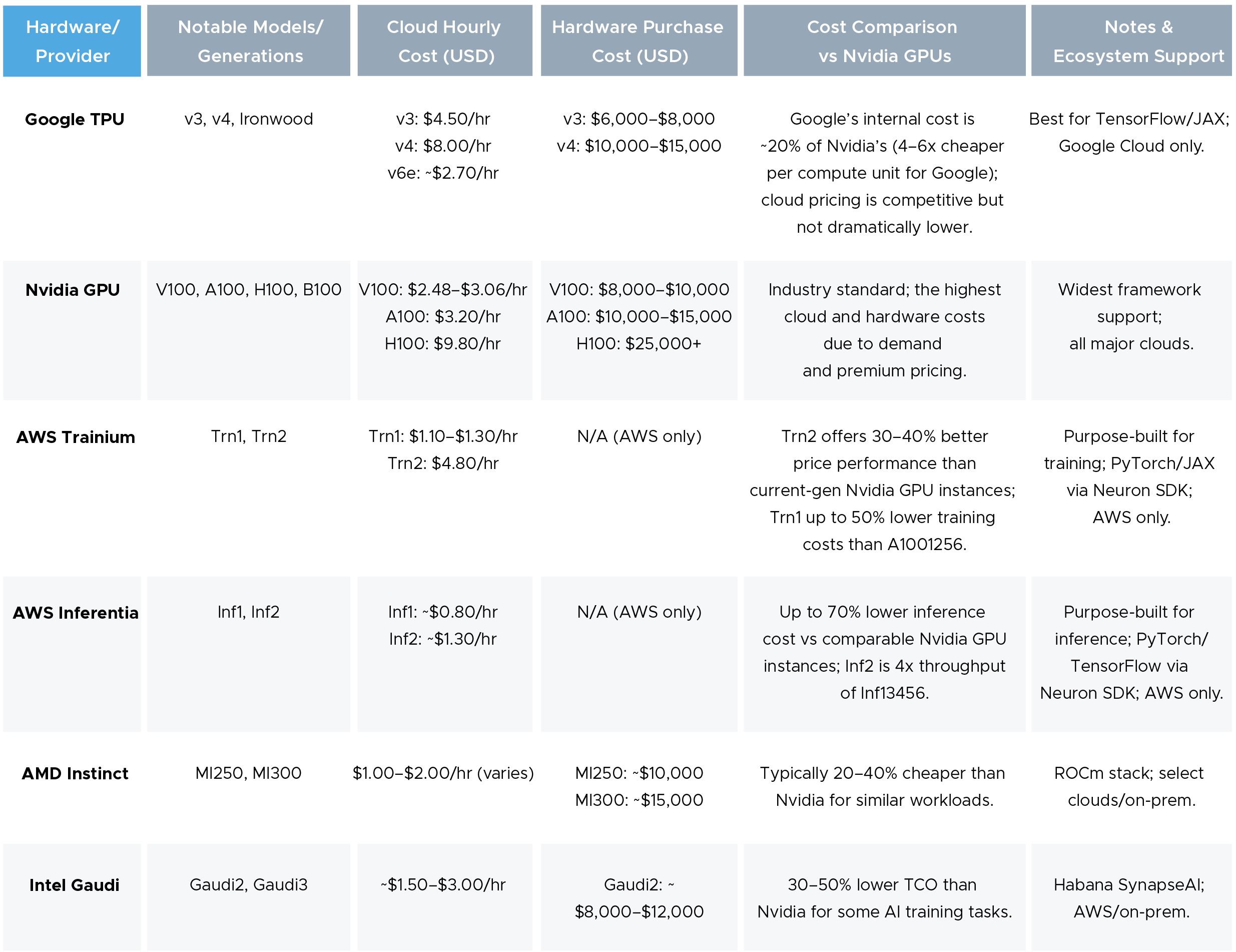
However, offerings from other vendors, such as AWS with Trainium and Inferentia, Google with its TPU, Intel with Gaudi, and AMD with Instinct, offer competitive pricing while matching the performance of similar offerings from NVIDIA, thus helping in AI cost optimization.
Here’s a holistic analysis comparing NVIDIA GPUs and the alternatives:
Use Spot Instances for Model Training
Spot Instances offer up to 90% discounts on compute resources compared to on-demand pricing. When used strategically, they can play a pivotal role in your AI cost optimization efforts.
The only drawback is that the cloud provider can reclaim these instances at any time. However, since you're only training the model and not running a production workload, Spot Instances shouldn’t be an issue.
But keep in mind to implement periodic model checkpointing to ensure that the model training process can resume once the Spot Instance becomes available again.
Offload Inference to Client Devices
While running heavy workloads and processing on your infrastructure, save processing power for critical tasks by shifting basic functions such as document summarization to client devices like Microsoft Copilot on Windows, Apple Intelligence, and others.
However, shifting workloads doesn’t necessarily result in low latency, and on devices with older hardware, it can lead to freezes and performance degradation, and consequently, harm user experience in your quest for AI cost optimization.
By offloading these simpler tasks, you can reduce strain on your primary compute resources and, as a result, cut down your cloud spend.
Fully Leverage Discount Plans
The most popular discount plans are from AWS, and they are driven by commitment. AWS Reserved Instances (RI) and the AWS Savings Plan (which also offers discounts for SageMaker) are the two primary options, providing discounts of up to 72% across various computing platforms.
You can also negotiate custom discounts through the AWS Enterprise Discount Program (EDP). However, Amazon EDP comes with significant constraints, including vendor lock-in. For better benefits without long-term commitments, check out EDP+.
By utilizing these discount plans, you can offset the higher costs associated with AI workloads by saving on other resources, such as compute, storage, etc.
Use Auto scaling for workloads
While AI workloads like data training typically remain consistently high, others can peak and drop, similar to traditional workloads. Since AI workloads are expensive, it’s important to scale down resources when not in use to avoid cost overruns to meet AI cost optimization targets.
Use Amazon EKS to manage clusters, leverage AWS Auto Scaling, or opt for advanced AI tools like CloudKeeper Tuner or CloudKeeper Auto for fully AI-managed resource utilization, so you only provision what you use.
Streamline AI Model Architecture
For cost optimization in AI, the conversation begins with the model itself being sorted to extract maximum performance per gigabyte. Here are some techniques that are widely implemented for model optimization:
Optimize workflow:
Consolidate API requests, as this will reduce the hit rate, and monitor and schedule regularly to know where the cloud spend is going.
This can be done by integrating cost-aware scheduling. For example, if you have to train a model, you can use AWS EventBridgeScheduler to schedule it on Spot Instances or during periods when the cloud provider offers lower costs.
Caching:
Implement caching by identifying redundant computations and repeated retrievals, as these consume cloud resources and impact your AI cost optimization strategy. This is particularly useful for inference workloads. Tools such as AWS ElastiCache simplify caching on AWS.
Task Segmentation:
Through segmentation, earlier, larger, and more complicated workflows can be executed separately. This facilitates scheduling of non-urgent segments during off-peak hours for temporal arbitrage.
Run models on serverless computing:
Running models on serverless computing resources like AWS Lambda is a good practice, and orchestration tools such as AWS Step Functions simplify doing so. However, Lambda works only for sub-1s inference.
Optimize AI Preprocessing
Processing precedes AI inference, which makes it a key driver of cloud spend and, as a result, something that needs to be optimized.
Function as a Service (FaaS) helps drive cost optimization in AI, as the platform provider’s instances execute code in response to predefined events.
AWS Lambda is the leading FaaS platform, costing $0.20 per 1 million requests, making it a significantly more cost-effective alternative to running a VM on a dedicated EC2 instance, all without compromising performance.
AI Cost Optimization Without Compromise: BMW’s Innovation Story
Document processing, compliance checks, and contract analysis are the tedious and repetitive tasks that many organizations try to tackle first when inducting AI into their workflow — and that’s what JP Morgan did with COIN, and that’s what BMW did as well.
Platforms used: BMW primarily uses AWS as its cloud provider, and, as a given, uses its AI services:
- SageMaker for model training and deployment
- Textract for text extraction from scanned documents
- Amazon Comprehend for NLP and entity recognition
BMW, from its vehicles alone, processes 10TB of data daily from 1.2 million vehicles. Beyond serving vehicle use cases, it manages more than 4,500 AWS accounts. As a result, optimization of cloud spend is a significant challenge — yet an important task — to avoid denting their revenue (pun intended).
How BMW Performs Cost Optimization in AI
BMW and AWS collaborated to build ICCA (In-Console Optimization Assistant), primarily built with AWS Bedrock, to help identify bloated resources and, as a result, assist their cloud engineers in AI cost optimization.
Under the hood, ICCA gains insights from AWS Trusted Advisor, a visibility platform that helps users optimize costs, and AWS Config, which audits and evaluates current configurations.
With ICCA alone, BMW Group reports that, on their AI-driven operations and some other workloads, they have saved up to 70% on processing costs.
BMW Group is a shining example of the fact that AI cost optimization does not result in hampered innovation.
How CloudKeeper Is Helping Organizations Rein In Their Cloud Spend
Beyond our tools, which serve a variety of functions from managing AWS RIs to automated provisioning and optimization, we’re a team of 100+ AWS-certified cloud professionals with 15+ years of experience, having saved over $120 million in cloud spend for our clients. Our savings span across compute resources, storage, contract negotiations, and configuration management.
Cut your cloud costs by an average of 20% starting day one. Join the growing list of organizations already saving with CloudKeeper.
Frequently Asked Questions
Q1:Should I go for cloud-based services or set up my dedicated infrastructure for AI workloads?
If your primary use case involves running AI services, then cloud infrastructure is a better choice. Setting up dedicated infrastructure is shockingly expensive — a single enterprise-level GPU setup from NVIDIA can cost up to $400,000, and that’s just the CapEx. You’ll still need to account for OpEx, including ongoing maintenance costs, which can amount to 3% of the hardware's value annually.
Q2:How to monitor my AI-specific cloud resource utilization?
Use AWS Cost Explorer filtered by SageMaker services and instance types to track spending, monitor GPU/CPU utilization in CloudWatch for idle resources, and set anomaly alerts—third-party tools like Datadog add deeper ML-specific insights if needed. With complete visibility, you can implement an accurate AI cost optimization roadmap.
Q3:What are the AI-specific drivers of cloud cost overruns?
The unpredictability of AI workloads often leads to overprovisioning, which is a major AI-related driver of cloud cost overruns — and a primary target in most organizations’ AI cost optimization strategies. To make matters worse, SageMaker instances cannot be sold on the Reserved Instance Marketplace, limiting an organization’s ability to recover unused spend.
Q4:How Does Model Quantization Reduce AI Costs?
Through quantization, a 32-bit machine learning model (where higher bit-width generally means higher precision) is reduced in precision while remaining sufficiently accurate. These smaller models assist in AI cost optimization, as they require fewer computational resources.
For example, reducing model weights from FP32 to INT8 brings the storage requirement down to just 25% of the original size. As a result, overall spend on AI workloads is significantly reduced.
Q5:What is cost optimization for AI?
In the context of cloud computing, AI cost optimization refers to maximizing the efficiency of AI computing resources by putting in place strategies such as tagging, instance right-sizing, autoscaling policies, commitment-based savings plans, and workload scheduling — strategies that facilitate cutting down cloud waste spend and extracting full potential out of your investment in cloud infrastructure.
Q6:Does AI help in cost reduction?
Absolutely! AI-powered tools such as CloudKeeper Tuner automate tasks like scheduling, shutting down idle resources, and right-sizing compute instances — all of which can help you realize significant savings on your next cloud bill.








