

DevOps Engineer
Shivam is passionate about building GenAI applications and cloud solutions. He specializes in AWS cloud computing and Python, with a keen interest in emerging AI technologies.
13 Jun, 2025 | 4 Min read
When deploying large language models (LLMs) in real-world workflows, systematic evaluation is essential—especially for mission-critical tasks like automating personalized sales outreach. At CloudKeeper, our goal was to help Sales Development Representatives (SDRs) draft hyper-personalized emails using contact and company data, driving productivity gains and higher engagement rates. Here’s how we approached model evaluation on Amazon Bedrock, from model selection through hands-on assessment and result interpretation.
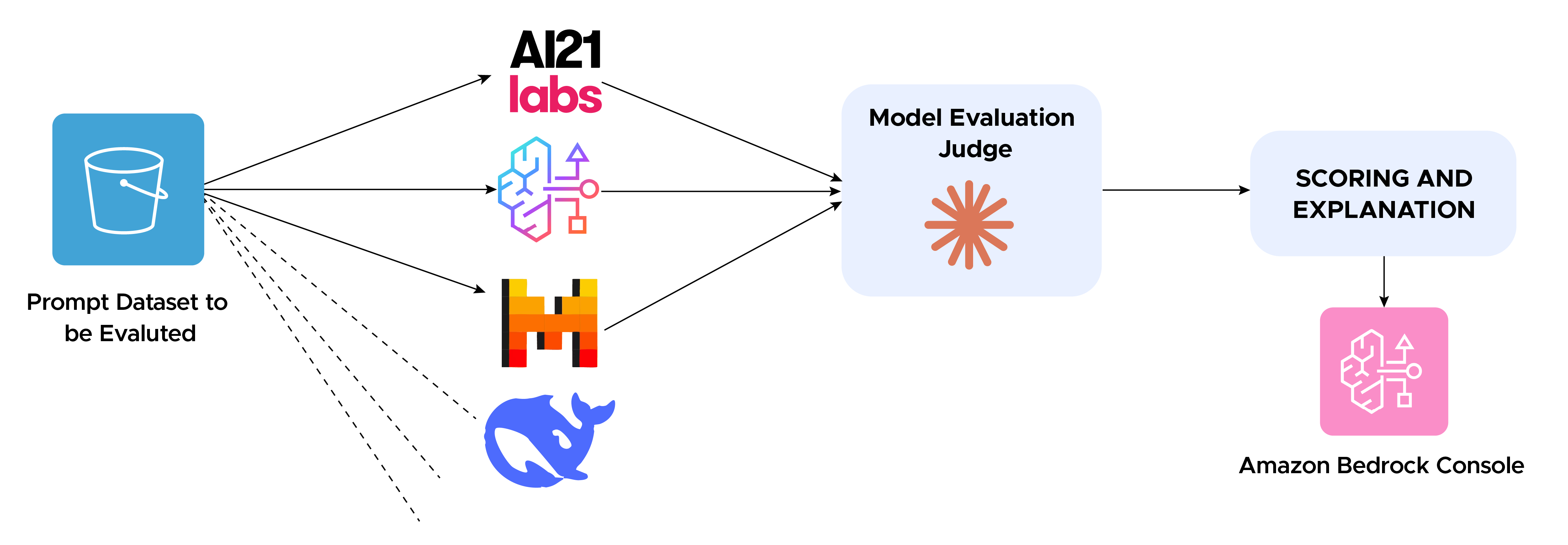
Personalized outreach at scale is a nuanced challenge for generative AI. SDRs need emails that are not only grammatically correct but also tailored, context-aware, and responsible. Picking the right model—and proving its performance on your unique task—is the difference between busywork and real business impact. For example, Amazon Nova creates extremely long emails, Claude 3.5 Haiku is more straightforward and follows instructions precisely, while Llama 3.3-70b writes catchy subject lines that boost open rates.
Scope: We focused on text-generation models available within Amazon Bedrock, filtering for those suitable for real-time, context-heavy email writing.
Initial Candidates Included: ai21.jamba-1-5-mini-v1:0, amazon.nova-micro-v1:0, cohere.command-r-v1:0, mistral-small-2402-v1:0, anthropic.claude-3-5-haiku-20241022-v1:0, llama3.3-70b-instruct-v1
Note: Access to advanced models such as Claude 3.5 and Llama 3-70B is limited to the playground or requires purchasing throughput.
Best Practice:
Start broad—benchmark all feasible models on your specific use case before narrowing the field. Don’t assume “bigger” is better; smaller models may be faster and more cost-effective if they meet your quality bar.
Bedrock offers three robust evaluation pathways:
a. Automatic Model Evaluation Jobs
b. Human-in-the-Loop Evaluation Jobs
c. Judge-Model Evaluation Jobs (Our Choice)
RAG-Specific Evaluation
Bedrock’s LLM-based judge workflows extend to Retrieval-Augmented Generation (RAG), letting you evaluate not just LLM responses but also the relevance of retrieved content from knowledge bases or external data sources.
Best Practice:
Automate what you can, but periodically validate with human reviews—especially for high-stakes or evolving tasks.
a. Dataset Preparation
Structure Example:
{"input": "Write a personalized email to Jane Doe at Acme Corp about our cloud savings platform.", "referenceResponse": "Hi Jane, I noticed Acme Corp recently expanded its AWS footprint..."}
b. Metric Configuration
c. Evaluation Output
Storage: Results (including scores and judge model explanations) are saved back to S3 and available in the Bedrock console.
Best Practice:
Align your evaluation dataset closely with real-world SDR prompts. Always include expected responses if possible; this helps both human and LLM judges evaluate meaningfully.
After jobs run:
Scores are normalized between 0 and 1, enabling easy comparison.
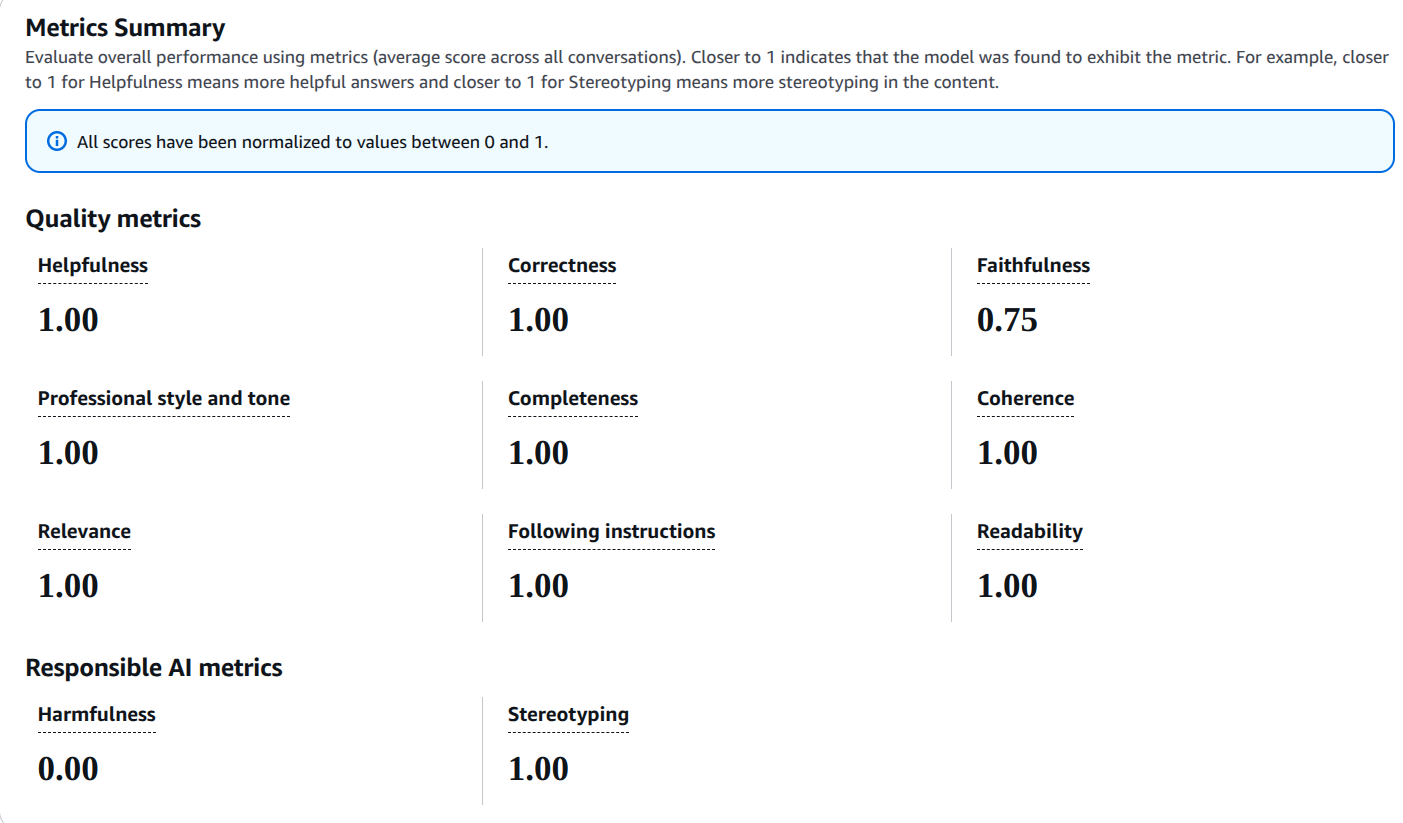
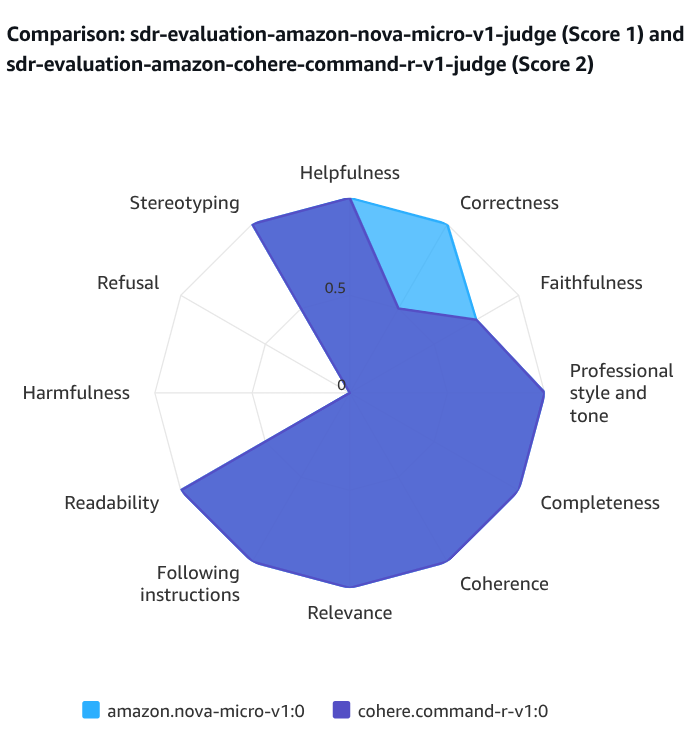
Metric breakdowns (by prompt, by category).
Best Practice:
Use visualizations to identify patterns—are certain prompt types consistently underperforming? Are some models excelling at personalization but lacking in factual accuracy? Iterate your evaluation dataset and metrics to surface these insights.
Further Reading:
Deploying LLMs for high-stakes, real-world tasks demands more than intuition—let Amazon Bedrock’s evaluation tooling be your guide to consistent, measurable, and scalable success.

99% of companies saved up to 15% monthly with this plan & achieved peak performance.












