

DevOps Engineer
Aditya is passionate about simplifying and strengthening Kubernetes operations on AWS. He works on improving cluster reliability, automation, and deployment efficiency in cloud environments.
19 Nov, 2025 | 5 Min read
If you’ve ever juggled workloads that need GPUs, FPGAs, or other hardware on Kubernetes, you know it can get messy. Until now, getting the right devices to the right pods without overprovisioning or starving your cluster was tricky.
With Kubernetes v1.34, that’s changing. The Dynamic Resource Allocation (DRA) framework has officially graduated to General Availability (GA), and it’s loaded with new powers. This update offers greater flexibility, control, and observability than ever before, from improved device sharing to real-time health reporting. Not only that, it also simplifies Kubernetes management. Learn more about smarter Kubernetes management here.
Fundamentally, Dynamic Resource Allocation facilitates dynamic management of specialised hardware by Kubernetes. Instead of hardcoding which GPU a pod gets, DRA lets workloads describe what kind of device they need, say, any GPU with at least 20 GB of memory, and leaves the scheduler to figure out the best allocation.
That means:
Imagine a team running both AI training and data preprocessing workloads. Training jobs need top-tier GPUs, while preprocessing can survive on mid-range hardware. DRA’s prioritised device list allows you to define acceptable alternatives, so if the best GPU isn’t available, the scheduler can automatically select the next best fit, thereby simplifying overall Kubernetes management. No manual reconfigurations.
With GA, DRA is a stable, default part of Kubernetes 1.34. The stable API (resource.k8s.io/v1) is on by default, so you can adopt it with confidence.
Several DRA features are promoted to beta in Kubernetes 1.34, providing developers and administrators with more precise control.
Admins can now use namespace labels to limit device usage. For instance, devices that grant elevated rights can only be used by namespaces that have resource.k8s.io/admin-access set to "true". By doing this, ordinary users can avoid inadvertently (or purposely) using high-privilege resources, which could result in privilege escalation.
For a task, you can now list several devices that are suitable.
Example (from a device request list or claim template) preferredEquipment:
The DRA-managed devices assigned to each pod are now reported by the Kubelet's API. This information can be used by monitoring agents to correlate hardware utilisation and pod performance.
Allows a smooth transition between DRA-managed devices and conventional extended resources. It merely indicates that devices under DRA management will be handled like any other resource.
Allows fine-grained sharing of devices like GPUs or NICs. Developers can allocate specific capacities (e.g., 10GiB out of a 40GiB GPU) safely. Consumable Capacity lets drivers expose a device’s total capacity and define policies for slicing it among multiple consumers across different Pods, namespaces, or claims.
We need to enable it on kubelet, kube-apiserver, kube-scheduler, and kube-controller-manager
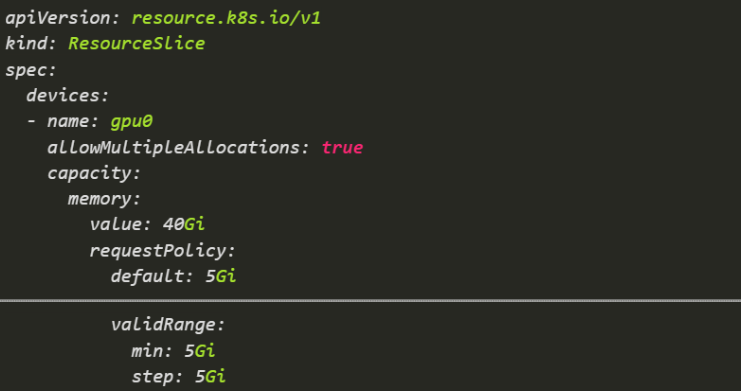
Allow multiple allocations on a device and define request policies for capacity units (min/step/default). With this we make a device within a ResourceSlice allocatable to multiple ResourceClaims just by doing this.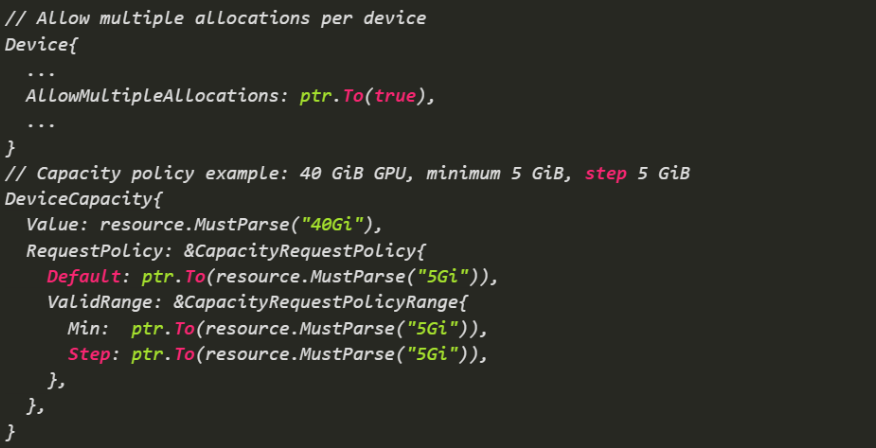
Request 10 GiB of memory from any device class `resource.example.com` that can satisfy it: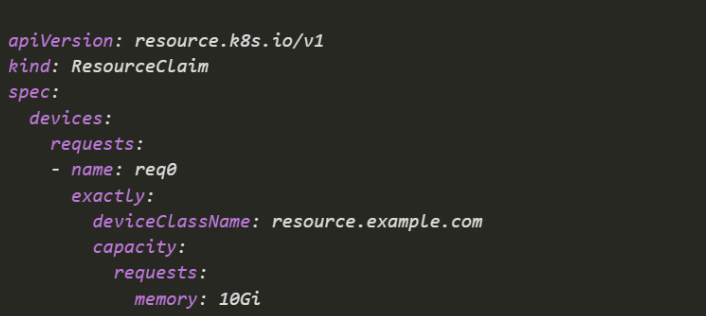
Filter only devices that support multiple allocations using a CEL selector:

After allocation, the status gains a per‑share identifier so your driver can distinguish and police each consumer independently:

The driver can differentiate between allocations that originate from distinct ResourceClaim requests but relate to the same device or statically-partitioned slice thanks to this ShareID.
It serves as a distinct identity for every shared slice, giving the driver the ability to autonomously control and enforce resource limitations among several users.
Kubernetes now reports device health directly in Pod status. Operators can instantly identify failing devices without deep debugging. The new health reporting for DRA feeds hardware health straight into the Pod’s status, so you can spot failing devices without checking logs.
How it works:
Enable the feature gate![]()
Kubectl Output Example
Between GA stability, beta flexibility, and alpha innovation, Kubernetes 1.34 makes DRA more than just a framework. It's becoming the foundation for modern hardware orchestration. As AI, ML, and edge workloads become the norm, DRA ensures hardware resources are used efficiently, dynamically, and safely. Kubernetes 1.34 gives you more control, better insight, and safer sharing, keeping your workloads humming across even the most demanding hardware.
Looking to optimise your Kubernetes at Scale? Whether you're just getting started or already running production clusters, CloudKeeper helps you achieve better performance, more control, and a lot of savings. Get a free assessment today!

99% of companies saved up to 15% monthly with this plan & achieved peak performance.

Speak with our advisors to learn how you can take control of your Cloud Cost





