
5
5Organizations use different architectural models (Serverless, Microservices, and Monolithic) to deploy their workloads on the cloud and implement the auto-scaling feature along with it, anticipating significant cloud cost savings. But auto-scaling by itself is an ‘overrated’ functionality and doesn’t result in effective cloud cost reduction, unless done right. Allow us to share a customer story that reinforces this notion and sheds light on the importance of proper implementation.
For this particular customer, we were planning to initiate a Savings Plan for AWS cost reduction and before purchasing it, we wanted to understand how their hourly spending varied throughout the day, weeks, and months. AWS savings plan recommendations provide excellent insights based on the different configurations available, payment options, and data set duration (7, 30, or 60 days), but we wanted to have a better understanding of their AWS stack and then make the decision on how much USD/Hour commitment should we make. This was quite difficult for us because of multiple reasons like lesser traffic on the platform, and additional cloud cost savings threads like downgrading instance types, and moving them to the latest generation.
Before getting into further detail, let us provide more context about the workloads running on the customer’s AWS setup. They have both monolithic (Magento stack) applications and microservices (React, Springboot, Django) deployed in AWS and aggressively use both on-demand and spot instances in the production environment.
To make sure that we were committing the right dollar value for the AWS savings plan, we wanted to review our EC2 capacity needs throughout the day, to better optimize the aws cost reduction practices. We proceeded with digging into the AWS console to see the number of EC2 instances running in the AWS account on hourly granularity. To my surprise, there was no option to view this data & we ended up writing our own script that pushes these insights into the influx every 5 minutes. We used Grafana to visualize the influx data and to make it more meaningful, we also added our primary load balancer request count metrics to view a daily trend.
Below is the screenshot of the Grafana dashboard with the initial data:
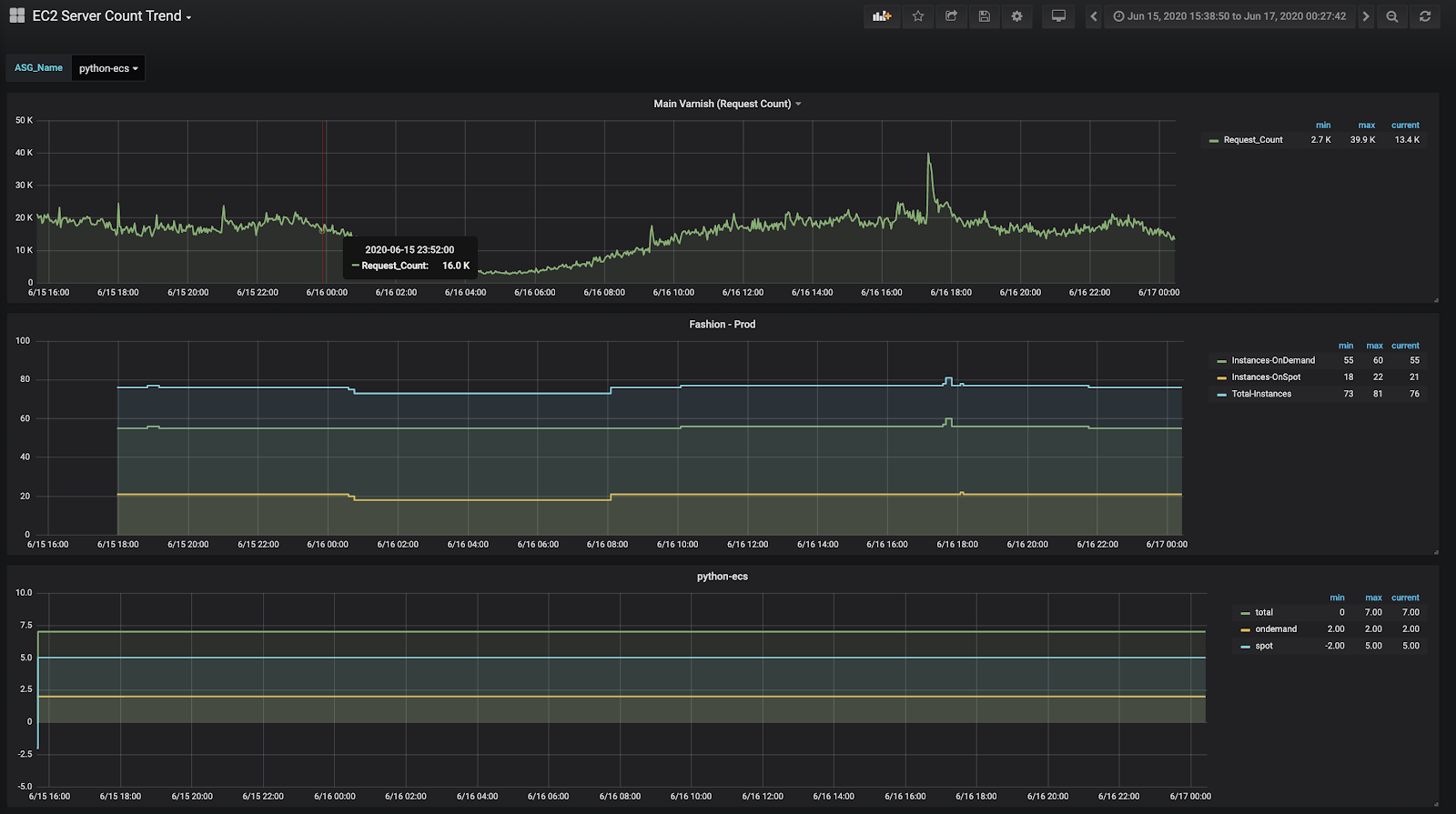
In addition to that, we also added the flexibility to choose from multiple auto-scaling groups using a drop-down. This visualization plots the graph for on-demand, spot, and total EC2 count for that auto-scaling group.
After analyzing the data for 1 week, we were surprised to see that even after using multiple auto-scaling groups, the number of servers remains consistent throughout the period of 1 week resulting in no significant cloud cost savings. Hence, no auto-scaling happened during the week, which meant that we were not leveraging the elasticity of the AWS cloud. Then we started reviewing configurations of every auto-scaling group and below are the high-level findings that we arrived on.
In a few of the auto-scaling groups, there were no scale-down policies attached, because of which, the servers were not turning off during the lean hours.
In a few of the auto-scaling groups, ineffective scaling policies were implemented i.e. auto-scaling was implemented on the high CPU, but workloads were more memory intensive.
One of the legacy (Magento stack) workloads were used to run the majority of the EC2 instances in the auto-scaling group. But we were not leveraging scaling policies because the initial uptime of the servers with code sync was very long. And we used to play safe here by over-provisioning the EC2 instances.
Do these findings feel relatable? They might.
So, we ended up optimizing the above-mentioned inefficiencies to enhance the AWS cost reduction results, by adopting target tracking scaling policies (request) for most of the workloads. For legacy workloads we initially started using scheduled scaling to immediately reap cloud cost savings. And in the longer run, we started using AWS auto-scaling group warm-up pools to reduce the boot-up times. Below is the screenshot of the same dashboard after making the relevant changes, which helped us to turn off around 25-30 servers during the lean hours. We could also address and resolve all the existing issues related to auto-scaling.
Here’s a whitepaper that might help you learn more about some of the best practices and the crucial considerations while implementing auto-scaling.
Hence, it is important to implement auto scaling the right way, which would not only make your workload more scalable but also ensure you take true advantage of the public cloud and achieve substantial cloud cost savings. Additionally, we would also like to encourage you to stay up to date on the latest features launched by AWS to make your workloads more efficient.
As and when you scale your cloud environment, implementing auto-scaling might get even more confusing. An experienced cloud FinOps partner like CloudKeeper could help you tackle this challenge and guide you through the best practices. Talk to our experts today!








