

DevOps Engineer
Abul specializes in Cloud Cost Optimization, FinOps practices, and GCP data solutions, combining technical expertise with strategic insight to drive efficiency and innovation.
BigQuery is the stage where data teams perform their boldest experiments. With a single query, petabytes of information bend into charts, dashboards, and insights in seconds. It feels limitless until the invoice arrives.
What looked like an elegant analysis can reveal itself as a runaway cost event. A dashboard refreshes every hour without filters. A developer casually runs SELECT * across terabytes. Or an entire historical dataset is scanned to answer a question about yesterday. Each of these decisions is invisible at first, but painfully clear when the bill lands.
This tension is what makes BigQuery fascinating: its brilliance lies in scale, but scale without discipline is expensive. Organizations don’t just need speed; they need control. They need a way to navigate the vast library of their data without wandering every aisle, to fly their analytical aircraft with pre-flight checks, to measure twice and cut once.
Such is the degree of speed and simplicity in using it that cloud engineers often automate BigQuery Audit Log collection to a centralized BigQuery dataset, thereby freeing up their time to focus on business-critical applications.
But speed without visibility is still a gamble. Queries may return results instantly, yet the cost and usage patterns often remain hidden. It’s like racing with a clear road ahead but no dashboard you can steer, and you can’t see fuel, performance, or strain on the engine.
What teams need are instruments that reveal not just results, but the economics and behavior behind them: who is querying, how much data is scanned, where inefficiencies creep in. The moment costs and performance become visible side by side, a new realm of insight opens, one where surprises turn into strategy, and that’s exactly where this story is headed.
In the sections that follow, we’ll look at seven practices that separate cost chaos from cost clarity. Think of them not as a checklist, but as a journey of architectural maturity. Each practice adds a layer of foresight, governance, and efficiency. Together, they transform BigQuery from a cost wildcard into a predictable, finely tuned part of your data strategy.
Challenge: Without partitioning, every query is forced to scan the entire dataset like rifling through every drawer in a filing cabinet to find one sheet of paper.
Strategy: Partition tables by ingestion date, timestamp, or another logical key. Think of it as constructing aisles in a warehouse: instead of walking through every corner, queries can head directly to the right aisle and scan only what matters.
Payoff: Partitioning often cuts scanned data by orders of magnitude, reducing costs while accelerating performance.
Challenge: Even within a partition, queries may still slog through irrelevant rows. A filter like “California customers in January” can still trigger a wide scan.
Strategy: Clustering sorts data inside partitions by frequently queried columns (region, product ID, etc.). It’s like pre-sorting mail by zip code before delivery for faster and cheaper than opening every envelope.
Payoff: When combined with partitioning, clustering ensures BigQuery skips massive chunks of data. Queries become more precise, costs drop, and dashboards load faster.
Challenge: SELECT * looks harmless, but BigQuery charges for every column scanned, even if you don’t use them. It’s the equivalent of ordering every dish on the menu when you only plan to eat one entrée.
Strategy: Always specify columns explicitly, or use SELECT * EXCEPT when flexibility is needed. This ensures your queries touch only what’s relevant.
Payoff: Eliminating SELECT * reduces both cost and query time. For large enterprises, this small shift often produces some of the biggest savings.
Challenge: Analysts often assume that adding LIMIT 100 reduces cost. In reality, BigQuery still scans the full dataset before trimming output. It’s like paying movers to carry every box out of the house just to keep one.
Strategy: Recognize that LIMIT is a display tool, not a cost-control mechanism. To meaningfully reduce costs, pair LIMIT with partition filters, clustering, or column selection.
Payoff: Teams stop leaning on false cost controls and instead adopt patterns that genuinely cut spend.
Challenge: Without foresight, queries run blind. A small mistake can trigger scans of billions of rows before anyone realizes.
Strategy: Use the BigQuery query validator or --dry_run flag. Dry runs estimate the exact number of bytes before execution. It’s a pilot’s pre-flight checklist: no engines start until fuel, hydraulics, and weather checks are complete.
Payoff: Expensive mistakes never take off. Teams refine queries confidently, knowing costs before committing.
Sidebar note: CLI dry-run example with estimated bytes scanned.
Challenge: Too often, costs are discovered when the invoice arrives far too late to act.
Strategy: Configure budgets and alerts in Cloud Billing and use the essential GCP tools for smarter cloud cost management. Alerts serve as dashboard warning lights: they flash when spend approaches thresholds, long before the engine overheats.
Payoff: Finance and engineering teams gain shared visibility. Surprises vanish, replaced by predictable cost governance and proactive adjustments.
Challenge: Cold, rarely accessed data quietly inflates storage bills, taking up premium space.
Strategy: After 90 days of no modification, BigQuery automatically halves storage costs. Beyond that, export archival data to Cloud Storage Coldline or Archive. It’s like moving old records out of prime downtown office space into a secure, low-cost warehouse.
Payoff: You maintain accessibility for compliance and history, but at a fraction of the cost.
Visual note: Lifecycle diagram “Hot data → 90 days → long-term pricing → archive.”
BigQuery is powerful. It can compress hours of analysis into seconds. It can turn petabytes of data into a single answer. But power without visibility leaves teams exposed. You can tune queries, partition tables, and set alerts, yet still be left wondering: Where did the cost really come from? Who is driving it? What's wasteful and what’s efficient?
That’s why we at CloudKeeper built the BigQuery Lens, an advanced dashboard that’s part of the CloudKeeper Lens.
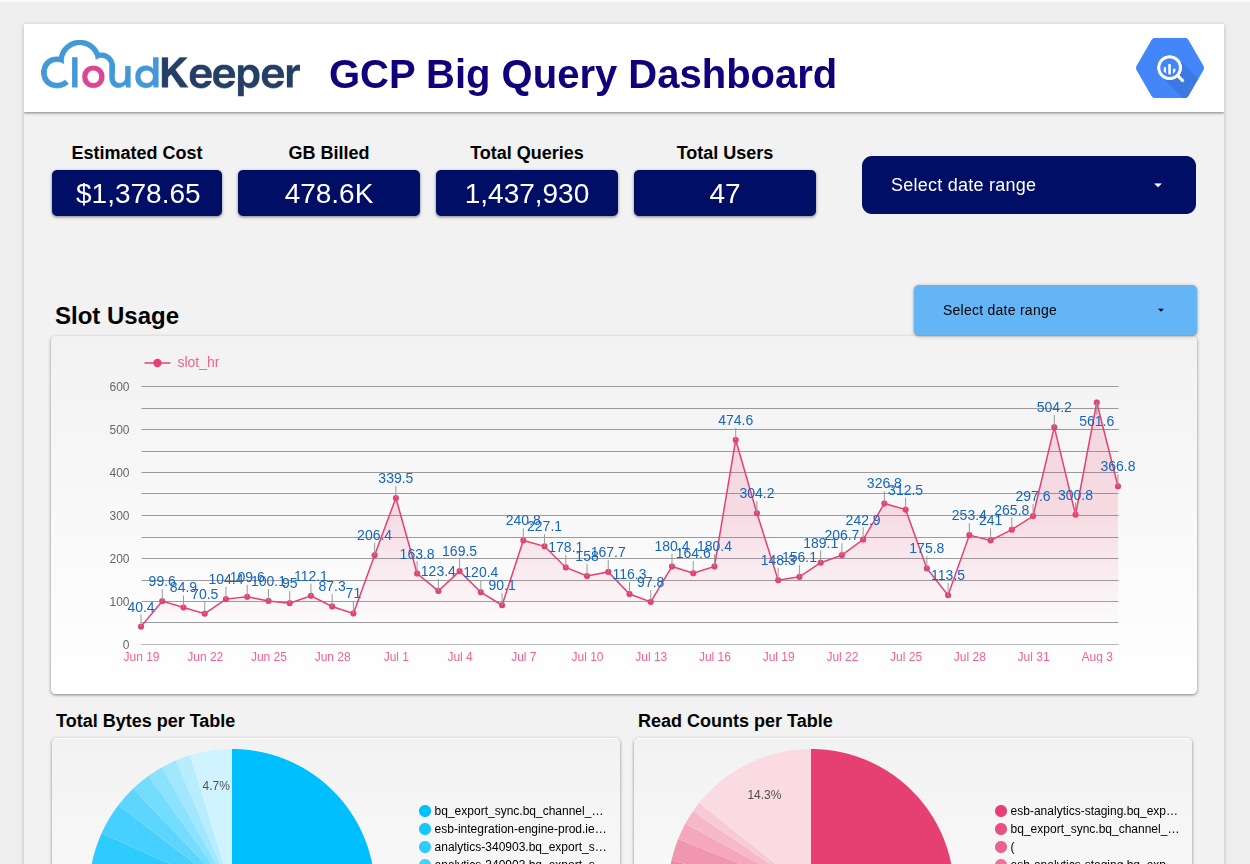
BigQuery Lens by CloudKeeper takes something complex, the economics of BigQuery, and makes it simple, elegant, and clear. For the first time, you can see cost and performance side by side, at the level where it matters: the query.
With BigQuery Lens, every job tells its story. You see which teams and projects are driving spend, which queries deliver value, and which are silently wasting resources. You discover cache savings you didn’t know you had. You uncover queries that scan terabytes to return only a handful of rows. You don’t just see the numbers, you see the patterns.
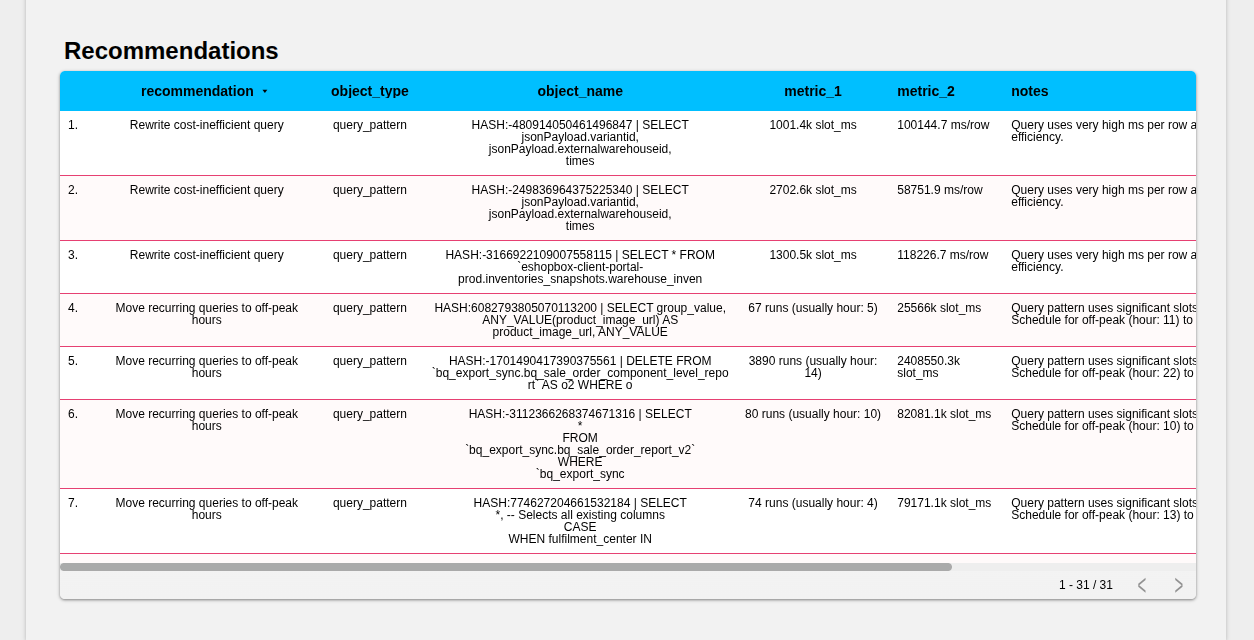
And because BigQuery Lens was designed for both engineers and finance, it becomes a shared language. Data teams learn how their choices affect cost. Finance teams see spending they can trust and explain. Leaders gain clarity at a glance.
This is not just another dashboard. It is a Lens that brings the hidden world of BigQuery into focus. With best practices guiding behavior, and BigQuery Lens illuminating the results, organizations move from uncertainty to control, from surprise to strategy.
Google BigQuery unlocked Data, CloudKeeper’s BigQuery Lens unlocks Understanding.

99% of companies saved up to 15% monthly with this plan & achieved peak performance.












