
10
10Serverless applications help businesses save the total cost of ownership (TCO) by effectively shifting operational responsibilities such as managing servers to a cloud provider. Since AWS Lambda is often the compute layer in the AWS serverless architecture workloads, it comprises a significant portion of the overall cost. Hence, understanding AWS Lambda Cost and methods to optimize your serverless applications can bring home the bacon.
Introduction to AWS Lambda pricing
Lambda's pricing is determined by three factors:
- The overall quantity of requests made.
- The total length of the invocations.
- The quantity of memory allocated.
Optimizing Lambda functions involves optimizing each of these components in order to reduce overall monthly expenses. This pricing structure becomes relevant once a user has exceeded the Lambda services that are offered for free by AWS.
Performance efficiency
Lambda pricing is largely determined by the overall duration of each invocation, which means that longer running functions will incur higher costs and increase application latency. Therefore, it is crucial to optimize your code for efficiency and adhere to Lambda's recommended guidelines to minimize these issues.
In order to improve the efficiency of code, it is important to optimize it at a higher level.
- One way to speed up the download and unpacking of deployment packages is to minimize their size by only including the necessary runtime components.
- Simplifying the dependencies in your code can also help to increase loading speed, especially if you use lightweight frameworks.
- For AWS Lambda’s performance optimization, try initializing SDK clients and database connections outside of the function handler and caching static assets locally in the /tmp directory. This approach can reduce the need to open new connections and resources with each invocation.
- It is essential to follow standard coding performance best practices for your chosen language and runtime to ensure maximum efficiency.
- To visualize your application's components and identify potential performance issues, consider using AWS X-Ray with Lambda. You can enable X-Ray active tracing on both new and existing functions by modifying the function configuration using the AWS CLI, for instance.

To trace all AWS SDK calls within Lambda functions, the AWS X-Ray SDK can be utilized, which aids in detecting any performance bottlenecks in the application. Additionally, the X-Ray SDK for Python can capture data for various libraries, including requests, sqlite3, and httplib, as exemplified in the following illustration:
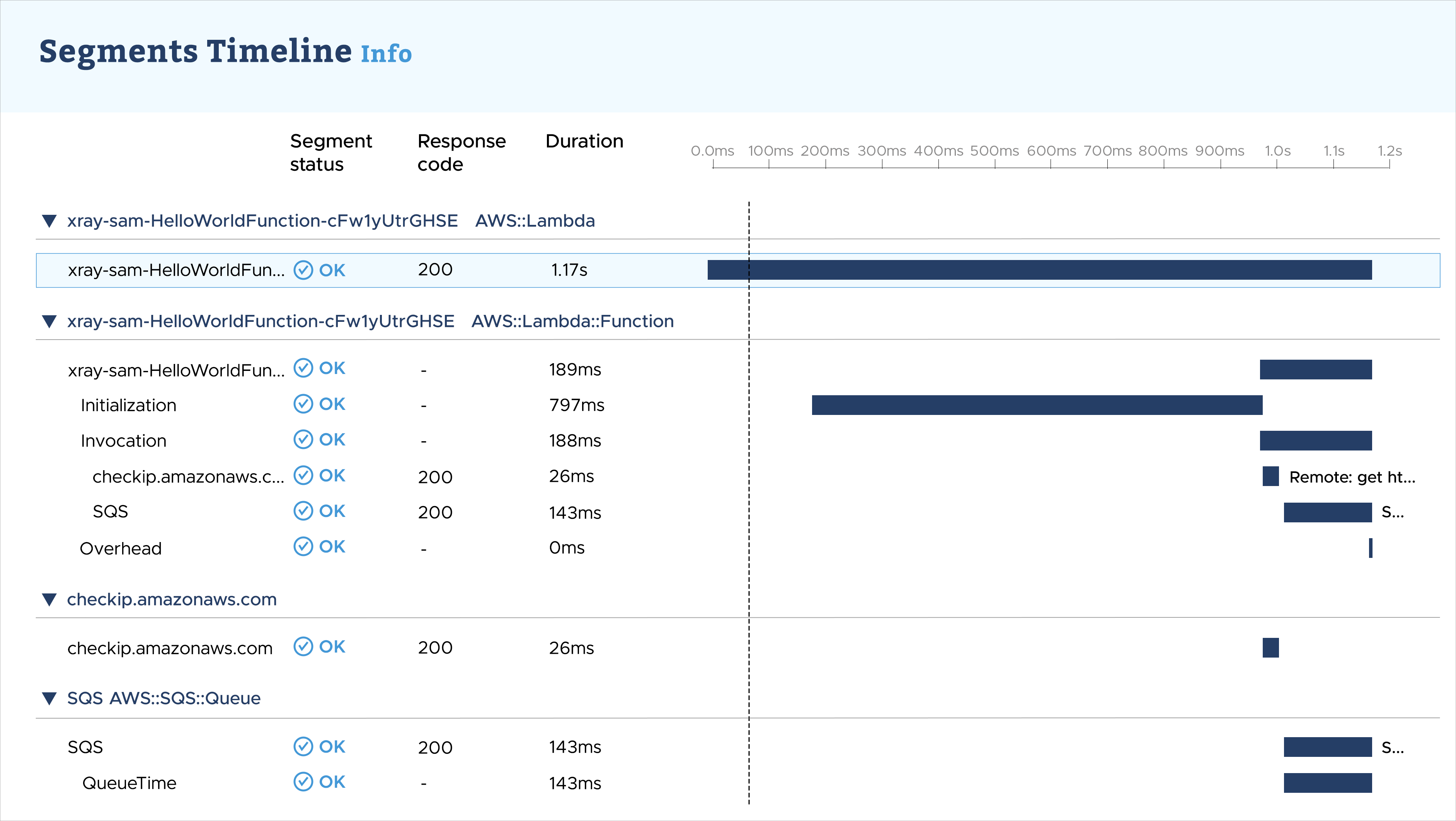
While building applications in an AWS serverless architecture, it is important to utilize both, established best practices and relevant tools, in order to assess your code's efficiency. By writing efficient code, you can achieve faster application performance and significantly lower costs.
Using AWS Graviton2
Lambda functions, which are powered by Arm-based AWS Graviton2 processors, were made available to the public in September 2021. These Graviton2 functions are specifically designed to deliver better AWS Lambda performance optimization (up to 19%) at a lower cost (up to 20%) compared to the x86 processors. By using Arm, you could also potentially reduce the function duration due to the improved CPU performance, leading to further cost reductions.
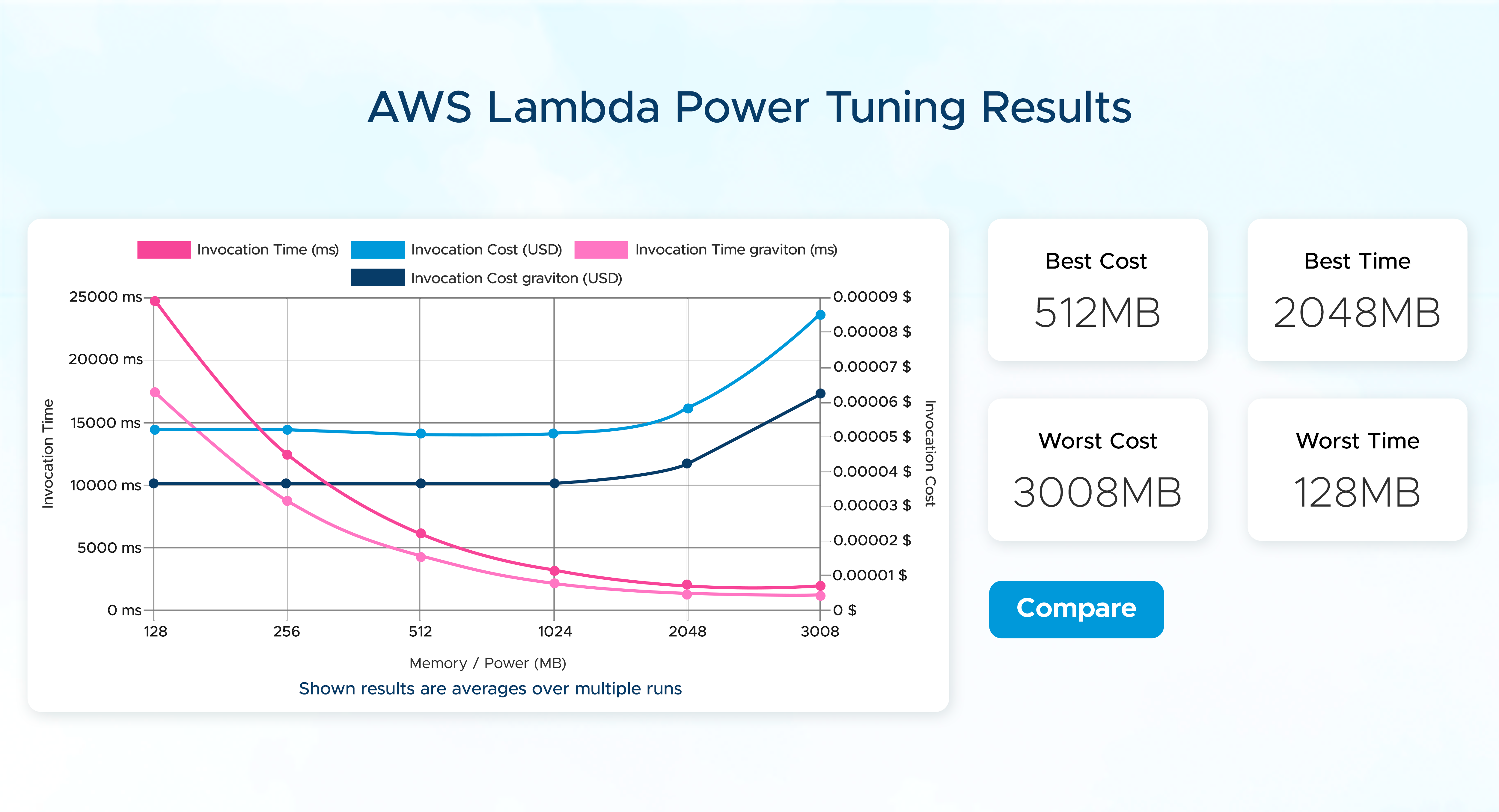
It is possible to configure both new and existing functions to target the AWS Graviton2 processor, and doing so won't affect how the functions are invoked or integrated with services, applications, and tools. While some functions may only require a configuration change to take advantage of the Graviton2 price/performance benefits, others may need to be repackaged to use Arm-specific dependencies.
To ensure a successful transition, it is recommended to test your workloads before making any changes. For this purpose, you can use the Lambda Power Tuning tool to compare the performance of your code against x86. This tool allows you to view and compare two results on the same chart.
Provisioned concurrency
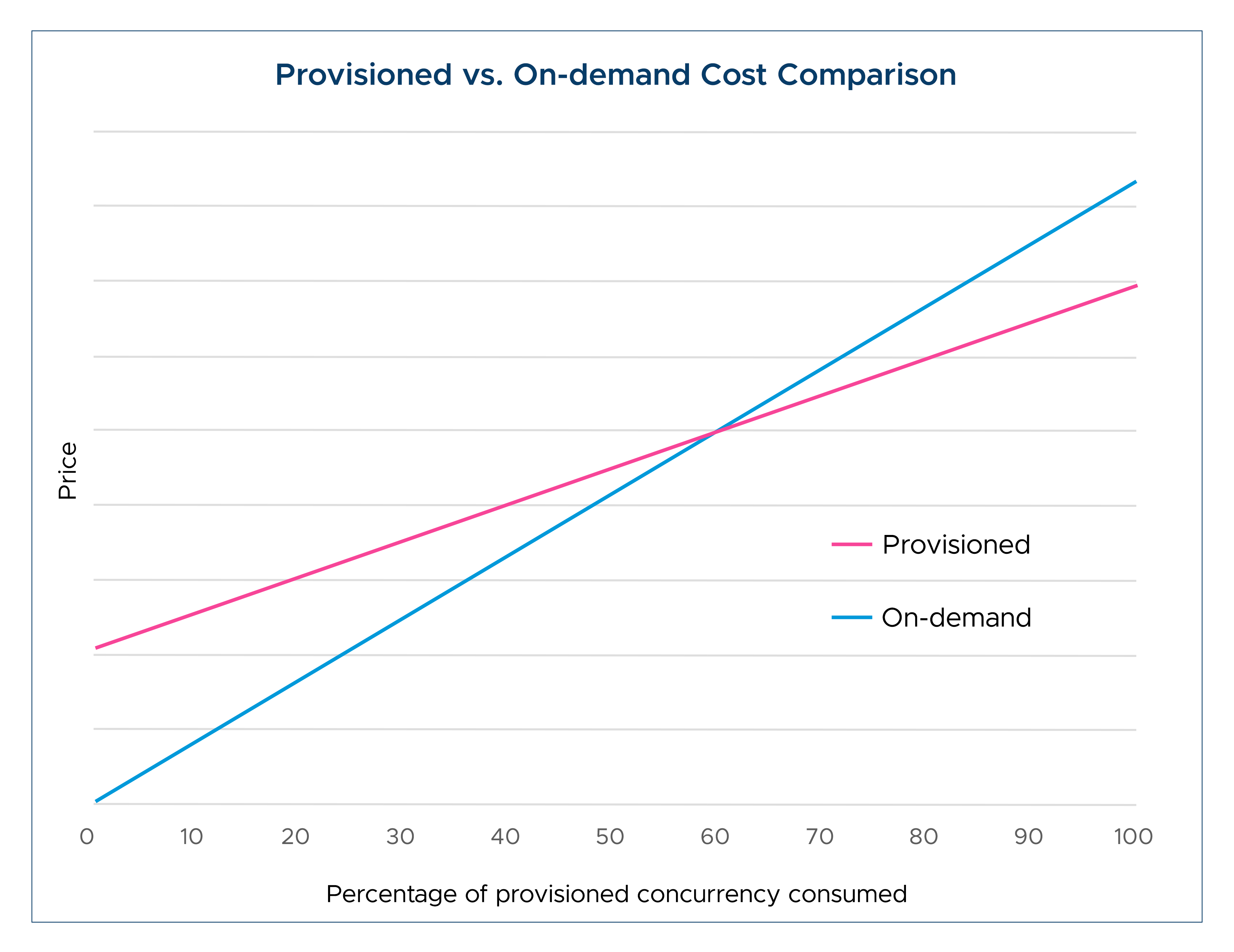
Provisioned concurrency enables customers to mitigate Lambda function cold starts and burst throttling by providing execution environments that are always ready to be invoked. The consistent volume of traffic here, can bring down AWS Lamda’s costs. The pricing model of provisioned concurrency comprises price components for total requests, total duration, and memory configuration, along with the cost of each provisioned concurrency environment based on its memory configuration.
Fully utilizing the execution environment of provisioned concurrency can result in up to a 16% reduction in duration cost compared to on-demand pricing. This is because the combined cost of invocation and execution environment is lower than the regular on-demand pricing. Even if the execution environment is not fully utilized, provisioned concurrency can still offer a lower total price per invocation. For instance, it becomes cheaper than on-demand pricing once it is consumed for more than 60% of the available time, and the savings increase with capacity usage.
To establish a Lambda function's baseline invocation rate, it's advisable to examine the average hourly metrics for concurrent executions during the preceding 24-hour period. This approach enables you to identify a stable baseline that accounts for the utilization of multiple execution environments over the course of the day.
Compute savings plans
AWS Savings Plans is a pricing option that offers reduced rates compared to on-demand pricing for a specific commitment of usage, which is measured in $/hour over a period of one or three years.
These plans cover various services such as Amazon EC2, AWS Fargate, and Lambda, with the latter being eligible for up to 17% discounted rates for usage that involves duration and provisioned concurrency, provided that a 1- or 3-year term is agreed upon.
Savings Plans can be implemented without requiring any changes to function code or configuration, making it a simple way to save money on Lambda-based workloads. However, it is important to analyze previous usage patterns to identify any variations before deciding to use a savings plan.
Event filtering
One of the widely used serverless architecture patterns involves configuring Lambda to receive events from a stream or queue, such as Amazon SQS or Amazon Kinesis Data Streams. To accomplish this, an event source mapping is employed to specify how the Lambda service processes incoming messages or records from the event source.
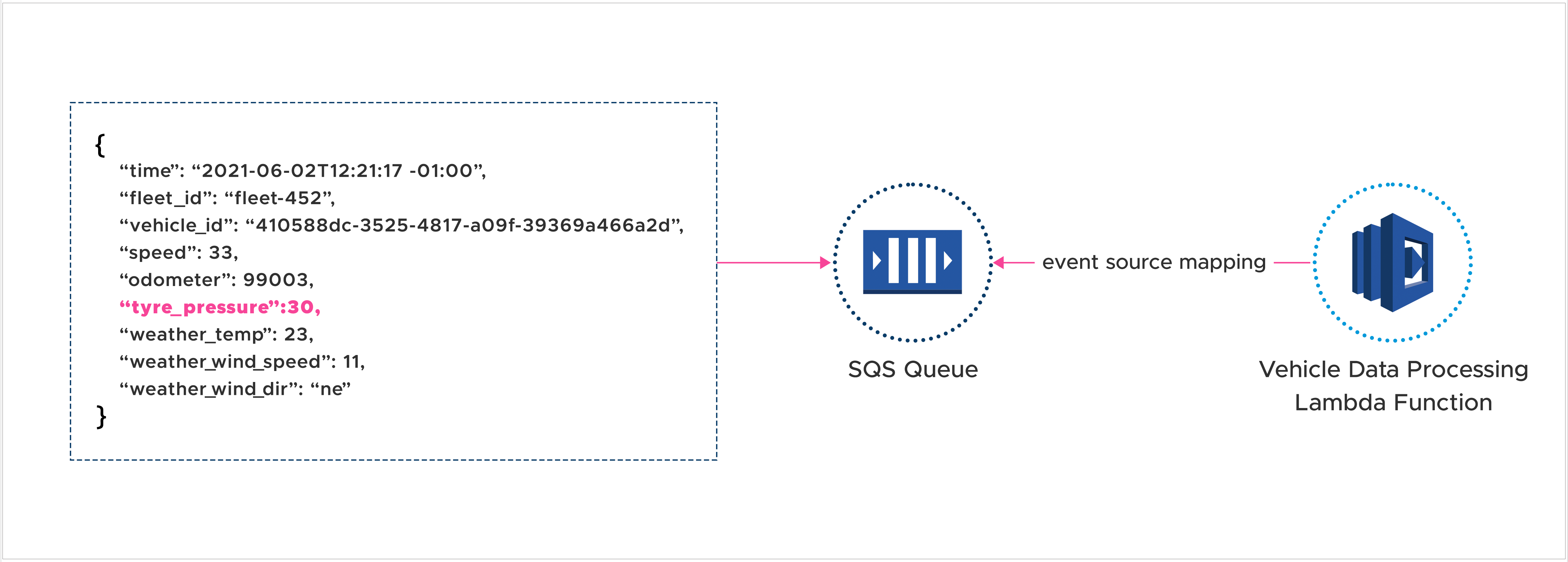
At times, it may not be necessary to handle all messages present in a queue or stream, especially if the information contained within is irrelevant. Consider an instance where data from IoT vehicles is transmitted to a Kinesis Stream and the objective is to only process events where the tire pressure is below 32. In such a case, the Lambda code could resemble the following example.

The current method of invoking and executing Lambda functions can be inefficient because it incurs costs for both invocations and execution time, even when filtering is the only business value.
However, Lambda now offers a solution to this problem. With the new feature, you can filter messages before the invocation, making your code more straightforward and cost-effective. This way, you will only be charged for Lambda when the event matches the filter criteria and triggers an invocation.
To implement filtering, simply specify the filter criteria when setting up the event source mapping for Kinesis Streams, Amazon DynamoDB Streams, or SQS. For instance, you can use the following AWS CLI command to set up filtering.

Lambda will be triggered only if the tyre_pressure in messages from the Kinesis Stream is less than 32 after the filter is applied. This could be a sign of a vehicle issue that needs to be addressed.
Avoid idle wait time
The duration of a Lambda function is a factor in calculating billing. If a function's code includes a blocking call, the time it spends waiting for a response is included in the billing. This idle wait time can become significant when Lambda functions are linked together or when a function acts as an orchestrator for other functions. This can add management overhead for customers with workflows, such as batch operations or order delivery systems. Additionally, it may be impossible to complete all workflow logic and error handling within the maximum Lambda timeout of 15 minutes.
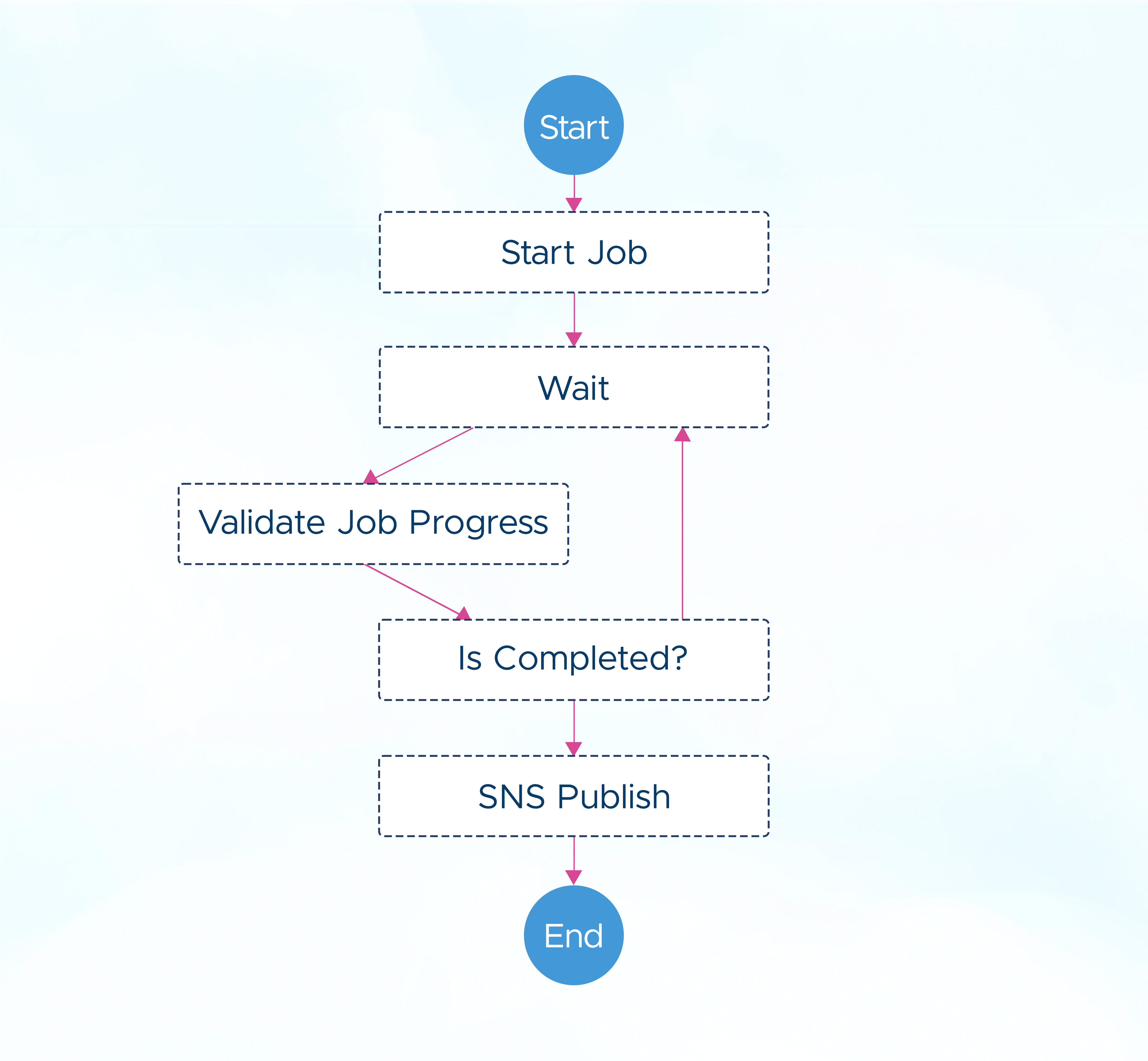
To address these issues, it's advisable to redesign the solution to use AWS Step Functions as a workflow orchestrator instead of handling the logic in the function code. With a standard workflow, you are charged for each state transition in the workflow, rather than the total duration of the workflow. Furthermore, you can move support for retries, wait conditions, error workflows, and callbacks into the state condition, allowing your Lambda functions to focus on business logic.
The following example illustrates a Step Functions state machine that divides a single Lambda function into several states. There is no charge during the wait period, and you are only billed for state transitions, hence promoting AWS Lambda optimization.
Direct integrations
If a Lambda function is simply acting as a pass-through to other AWS services without any custom processing, it might not be essential and an alternative direct integration option that is less expensive could be considered.
An instance of this could be utilizing a Lambda function with API Gateway to retrieve data from a DynamoDB table.
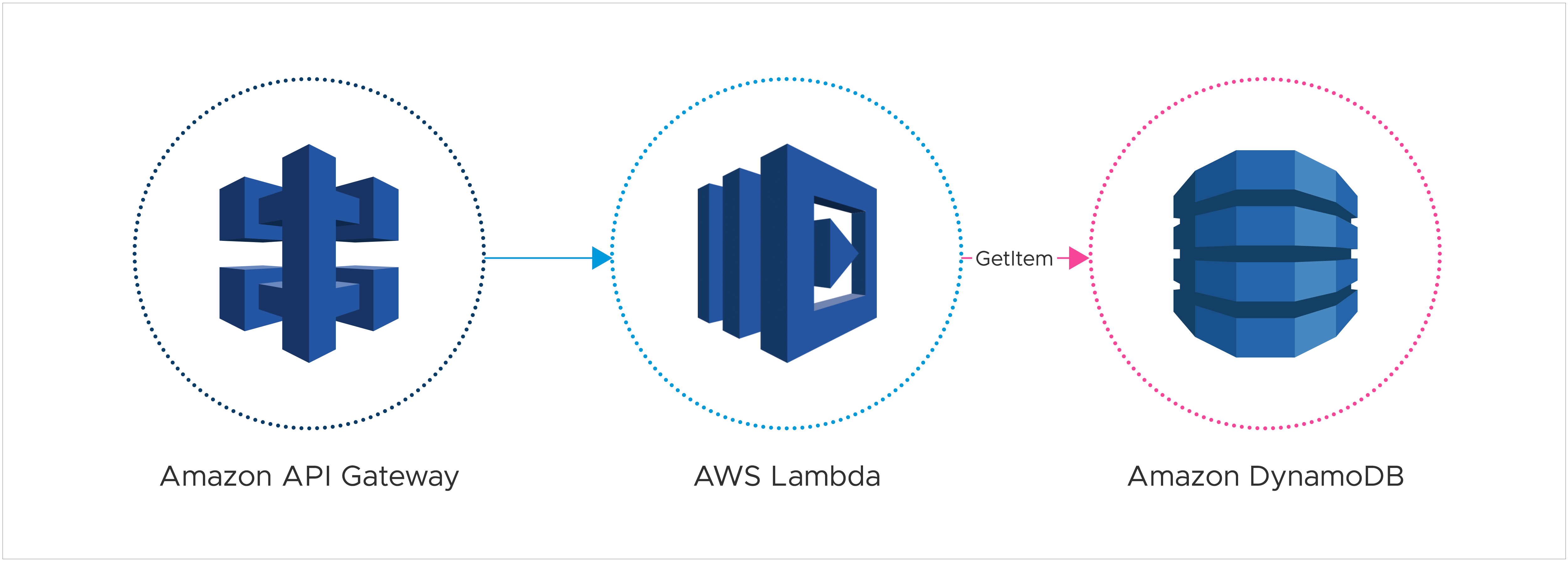
This could be replaced using a direct integration, removing the Lambda function:
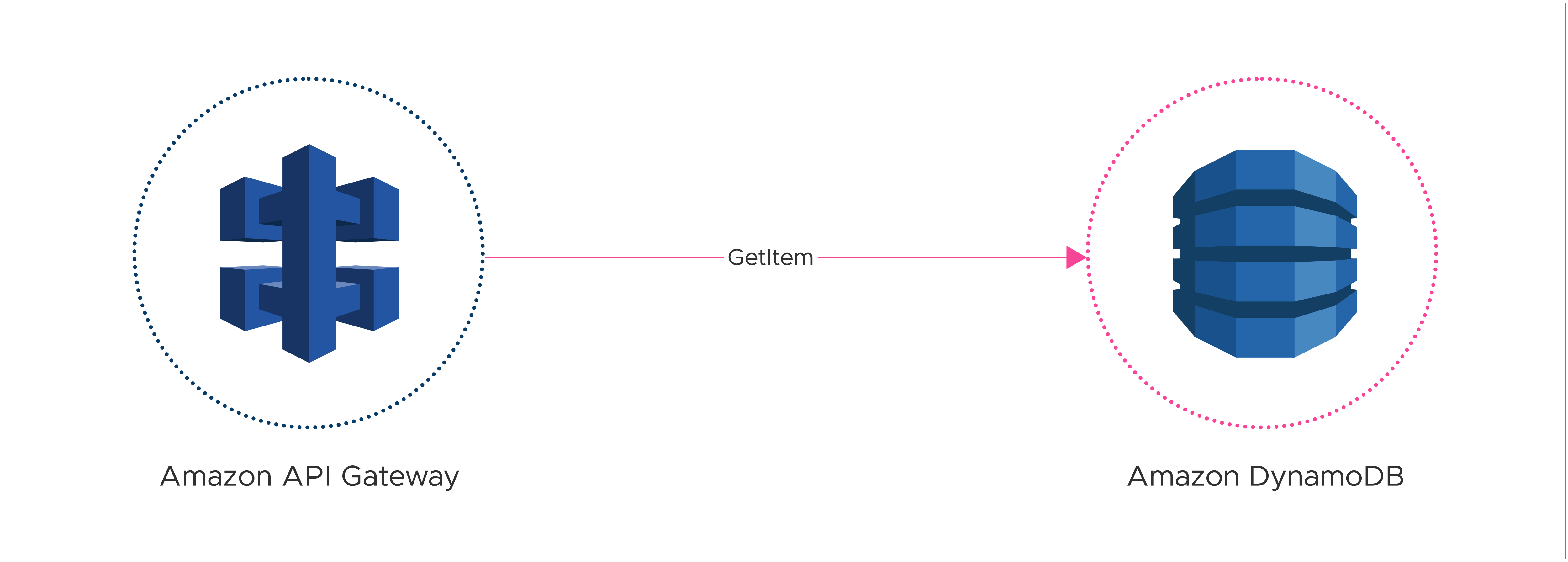
The API Gateway allows for custom response transformations, enabling clients to receive output in their desired format without requiring a separate Lambda function for the conversion.
Direct integration with AWS services is also available through Step Functions, which supports a wide range of services and API actions. This eliminates the need for a proxy Lambda function in many cases, simplifying workflows and substantially lowering compute costs.
Reduce logging output
Lambda automatically stores logs generated by function code through Amazon CloudWatch Logs. This feature can be valuable for gaining insights into your application's real-time behavior, but keep in mind that CloudWatch Logs incurs charges for the amount of data ingested each month. To keep AWS Lambda cost under control, it's best to limit the amount of data you output to only the necessary information.
When preparing to deploy workloads into production, it's essential to review your application's logging level. In pre-production environments, debug logs can be beneficial for fine-tuning the function, while in production workloads, you may want to disable debug-level logs and use a logging library like Lambda Powertools Python Logger. By defining a minimum logging level via an environment variable, you can configure the output without modifying the function code.
Structuring your log format with a defined schema can help enforce consistency and reduce the amount of text in your logs. For example, defining error codes and associated metrics can make it easier to filter logs for specific error types, reducing the risk of mistyped characters in log messages.
Use cost-effective storage for logs
The monthly storage fee for logs is per-GB. However, as log data gets older, its value diminishes, and you may only need to review it historically as and when needed. The pricing for CloudWatch Logs storage, however, remains the same.
To solve this issue, you can define retention policies on your CloudWatch Logs log groups to automatically remove old log data. This retention policy applies to both current and future log data.
Certain application logs may need to persist for several months or years to comply with regulatory requirements. In such cases, instead of keeping the logs in CloudWatch Logs, you can export them to Amazon S3. This approach will enable you to leverage lower-cost storage object classes while considering the anticipated usage patterns for the data and help you cost-optimize the Cloudwatch logs.
Save on your AWS Lambda pricing - a wrap-up
Ensuring cost optimization is crucial when creating well-architected solutions, and this holds true for serverless architectures as well. In this blog series, we delved into some best practices to help you reduce your AWS Lambda costs.
If you're currently running AWS Lambda applications in production, you'll find that some of these techniques are easier to implement than others. For instance, purchasing Savings Plans is a quick fix that doesn't require any changes to your code or architecture. However, eliminating idle wait time will require new services and modifications to your code. Before making any changes to your production environment, it's important to assess which technique is appropriate for your workload by testing it in a development environment.
CloudKeeper by To The New is an end-to-end FinOps solution that helps customers seamlessly manage all three stages of FinOps with its savings, software, and services offering.
Talk to our experts who will guide you through AWS Lambda performance optimization and give you a walkthrough on how to make additional savings on your AWS Savings/RI plans, without any lock-in commitment.








