

Cloud Engineer
Rishabh is a result-driven engineer with expertise in AWS cloud infrastructure, cost optimisation, and secure solution design.
Amazon Aurora DSQL (Distributed SQL) introduces a modern approach to relational databases by leveraging a distributed SQL architecture. This design delivers scalability, availability, and robust support for distributed transactions. However, adopting Aurora DSQL requires more than just excitement—it’s essential to understand its inner workings and evaluate whether your workload patterns align with its capabilities.
In this post, we’ll unpack how Aurora DSQL functions, explore the data patterns it’s best suited for, and provide insights to help you assess whether it’s the right fit for your use cases. Also, you should explore the difference between Amazon RDS and Amazon Aurora; this will further enhance your understanding of this concept.
Aurora DSQL’s power lies in its disaggregated architecture. Unlike traditional monolithic databases, it divides core functions into independent, scalable services. Each component can expand as needed, while cloud networking—with its high bandwidth and speed—keeps everything working seamlessly together.
This approach strikes a balance between performance, scalability, and consistency, while enabling distributed transactions across nodes.
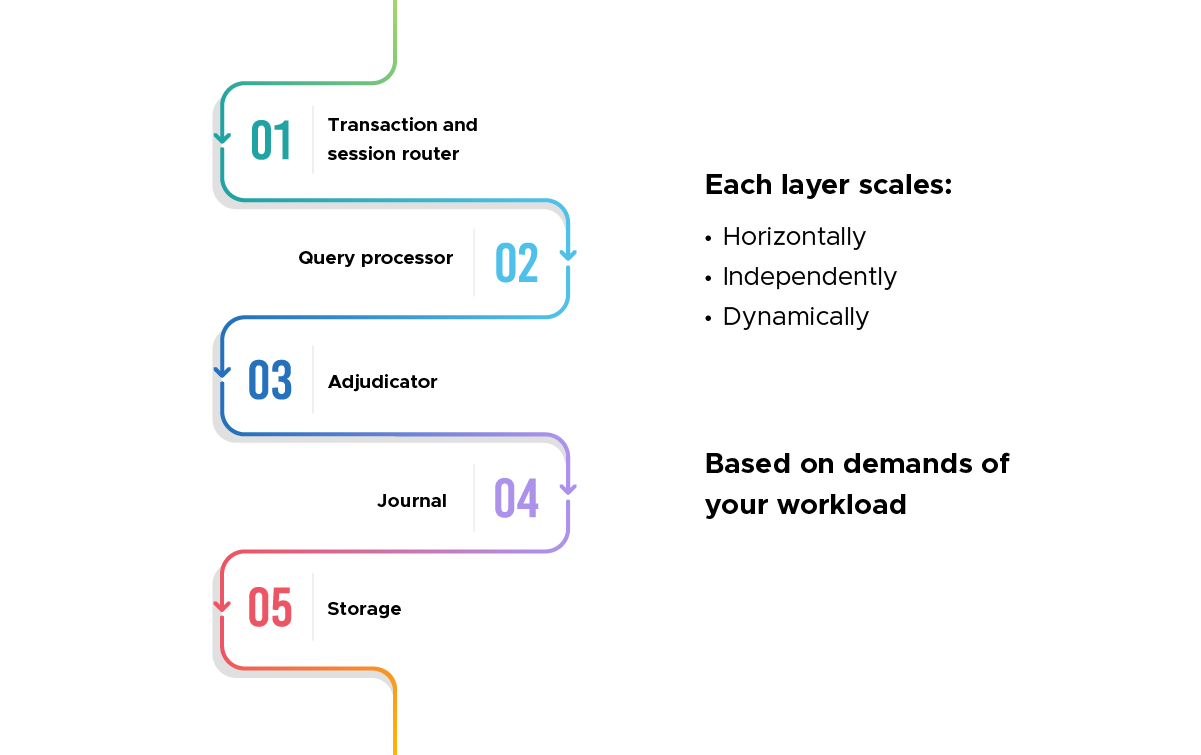
Amazon Aurora DSQL consists of the following elements:
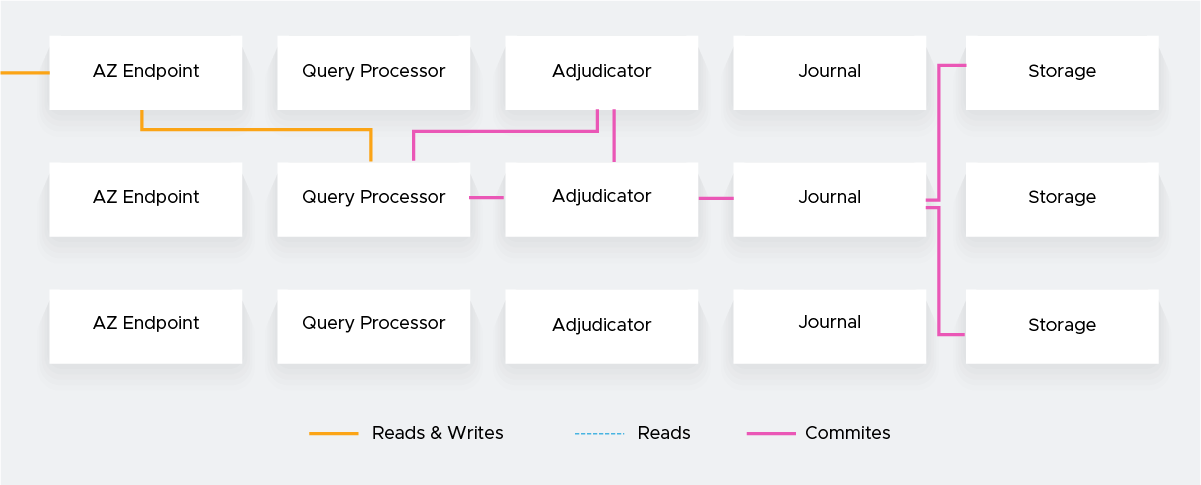
The operation when reading and writing is as follows.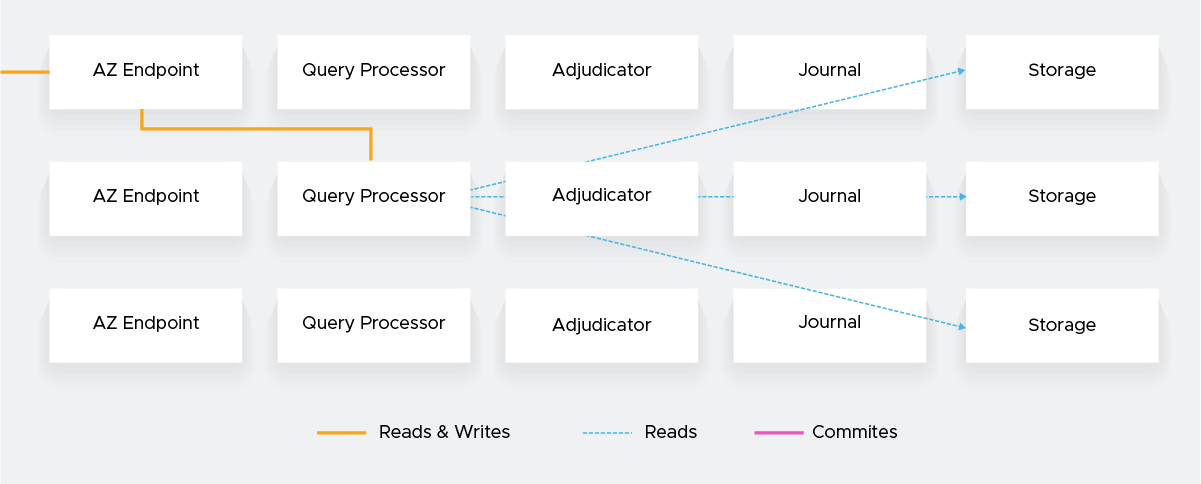
Let’s look at each element.
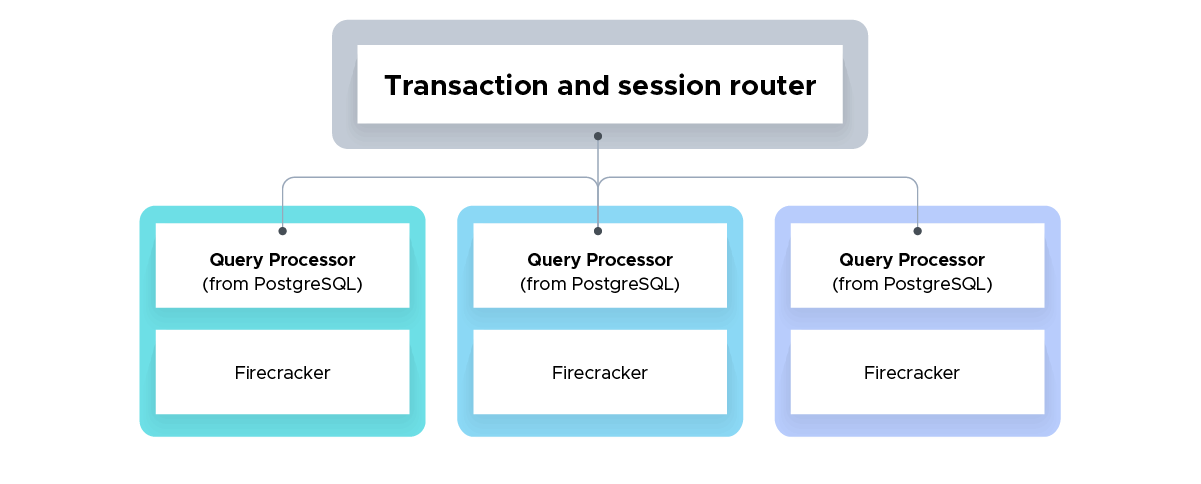
The PostgreSQL-compatible SQL engine Firecracker runs on a lightweight Firecracker-based virtual machine. QPs are scalable and dynamically increase or decrease according to client demand. Each transaction runs on a separate QP and is connected to the Storage in a logical interface.
All read queries are run in the snapshot isolation and refer to the data state at the start. Changes are saved locally until commits, even during write operations, and a distributed integrity check occurs only when committing.
It is a lightweight component that detects collisions during transaction commits. With an OCC-based architecture, Adjudicator does not hold a lock to an execution transaction, but determines a collision with a validation just before the commit.
This Adjudicator is close to stateless and can be reconfigured from the committed transaction logs, making it easy to restart when a failover occurs.
Record this at the time of the transaction commit. At this point, the transaction is permanently and atomically committed, and then the Storage shard applies the Journal to reflect the final state.
This approach achieves efficient durability and availability without complex distributed consensus protocols such as 2PC (two-phase commit) and Paxos/Raft.
Manage data with multiple Storage shards and replicas via the Distributed Journal .
MVCC provides a data view at any point in time, and QPs can access Storage with a linear logical interface. In addition, the storage layer reduces the number of network reciprocating times by pushing down some processing, such as filtering and aggregation, to the requests received from QPs.
Single-region configuration
The single-region configuration consists of distributed storage across three AZs, a group of scalable QPs, Journal, and Adjudicator.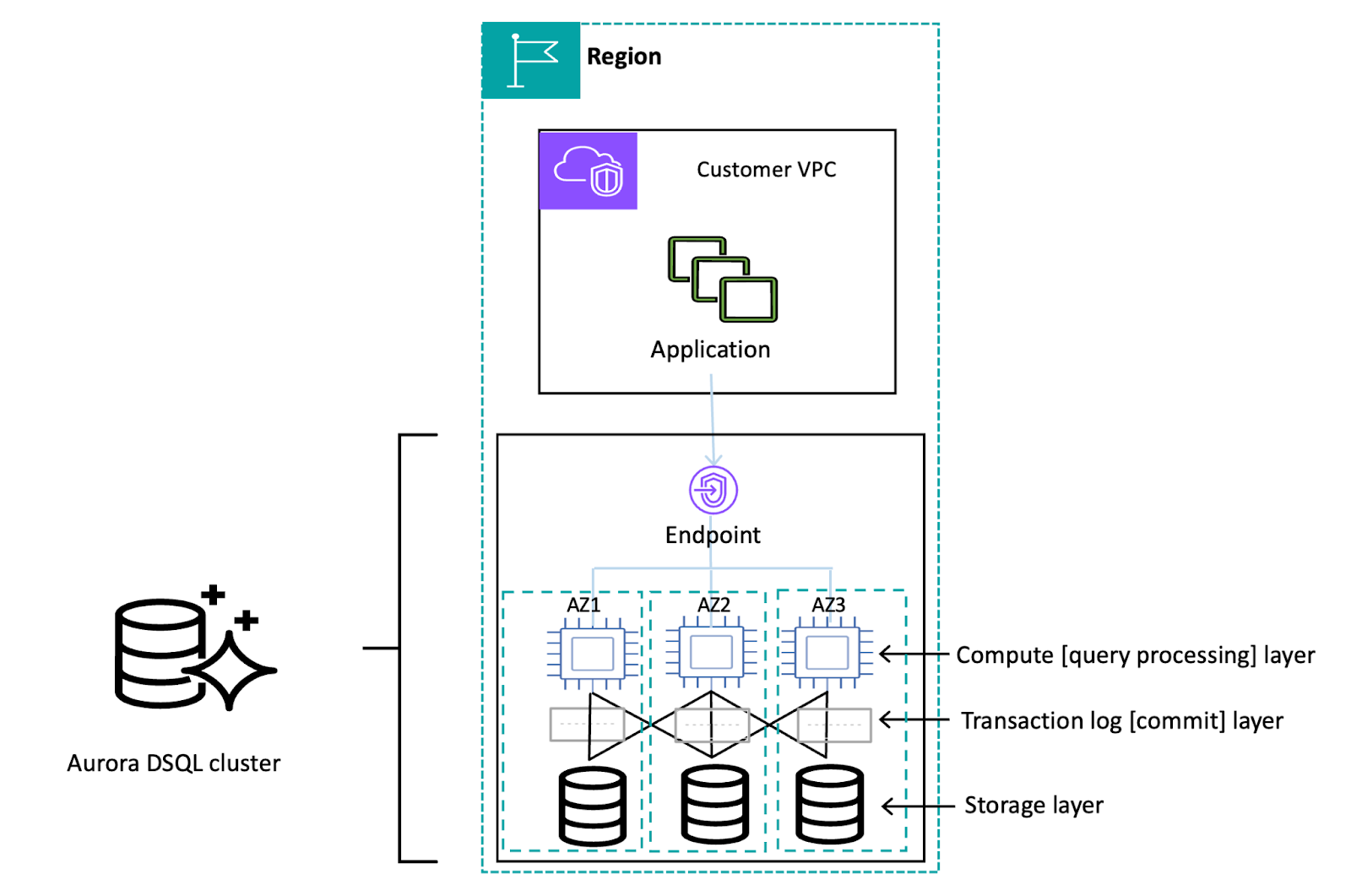
The write transaction is committed to the distributed transaction log, and the data is synchronously reflected in the storage replica across 3 AZs. This replica is efficiently distributed throughout the storage fleet to maximize database performance.
In addition, the system has a built-in automatic failover function that automatically switches to a healthy resource in the event of a component or AZ failure. The failed replica is then repaired asynchronously, and as soon as the restoration is complete, it is re-embedded into the quorum and made available as part of the cluster. This process ensures high availability and reliability.
In a multi-region configuration, we provide resiliency and connectivity, as well as in a single-region configuration, while leveraging 2 region endpoints to further increase availability. The endpoints of these linked clusters act as a single logical database, allowing simultaneous read-write operations while maintaining strong data integrity.
This mechanism allows applications to flexibly choose their connection destination according to their geographic location, performance requirements, and fault-tolerant needs, providing consistent data whenever they read.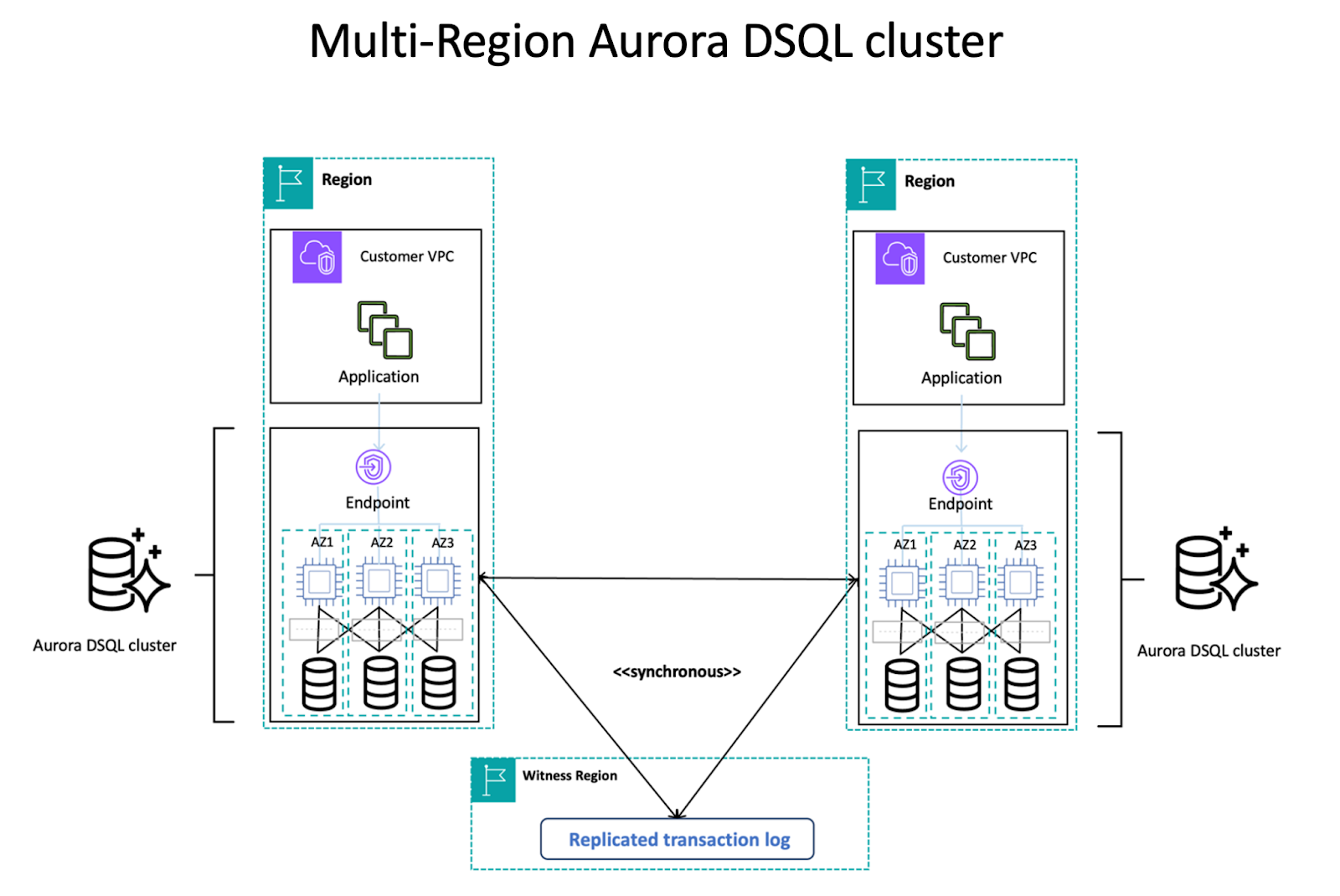
When you create a multi-region cluster, Amazon Aurora DSQL also adds clusters to another region specified and links them. With this link, all committed changes are replicated to other linked regions. This makes it possible to read and write strongly from any cluster.
Aurora DSQL is an excellent solution for modern distributed applications—especially those requiring high concurrency, global reach, read-heavy workloads, or partitionable writes. At the same time, it comes with trade-offs such as retries for optimistic locking and query timeouts that demand careful application design.
By aligning your workload patterns with Aurora DSQL’s strengths, you can unlock unmatched scalability, performance, and resilience compared to traditional relational databases. For the right workloads, it represents a major step forward in database architecture.

99% of companies saved up to 15% monthly with this plan & achieved peak performance.

Speak with our advisors to learn how you can take control of your Cloud Cost





